Description
The corpus of written narratives is a corpus of texts produced by primary school children (second and third graders) obtained within PIPALE as an answer to a written composition item that integrates the diagnosis instrument developed by the project’s team.
The diagnosis instrument PIPALE contains four Booklets. Each Booklet assesses different domains of language awareness and written language skills. The item that assesses compositional writing is part of Booklet 4 and elicits the production of a short narrative text by means of a sequence of three images, as exemplified below. Each image may be associated with a key moment of a narrative sequence: initial situation, problematic situation, resolution.
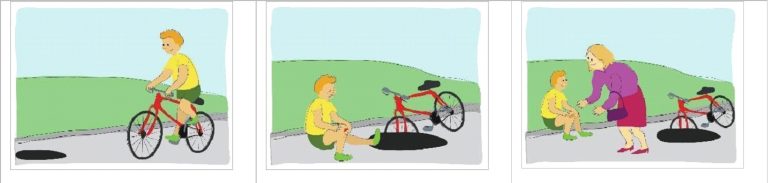
There are several versions of the diagnosis instrument PIPALE. Therefore, the texts may have been elicited by different sequences of images. However, the instruction given to the children is always the same: “Observe the images. Write a story about the sequence of images. Give a title to your story”. After the instruction and the sequence of images, there are 10 lines available for writing the text.
In what concerns the methodological procedures, the written task is completed in class by the main class teacher, with the support of PIPALE research team. The task is applied at four different moments: beginning and end of second grade and beginning and end of third grade.
The corpus is permanently being updated, with the inclusion of new texts in each academic year. Currently, it comprises narratives written between 2019 and 2024, by students of different schools from the Municipalities of Sesimbra and Seixal.
Each text was anonymized, digitalized and transcribed, and it is preceded by metadata with information on the sociolinguistic profile of each child and on the context of data collection.
Written narratives corpus | ||||||
Version of the diagnosis instrument PIPALE | Number of texts | Number of words | ||||
2nd grade | 3rd grade | Total | 2nd grade | 3rd grade | Total | |
Instrument 1 | 158 | – | 158 | 5324 | – | 5324 |
Instrument 2 | 145 | 82 | 227 | 7170 | 6194 | 13364 |
Instrument 3 | 72 | – | 72 | 4883 | – | 4883 |
Instrument 4 | 80 | 84 | 164 | 3809 | 4705 | 8514 |
Instrument 5 | 68 | 73 | 141 | 5352 | 5622 | 10974 |
Instrument 6 | 202 | 87 | 289 | 7663 | 6676 | 14339 |
Instrument 7 | 131 | 64 | 195 | 9599 | 6098 | 15697 |
TOTAL | 856 | 390 | 1246 | 43800 | 29295 | 73095 |
Access
The corpus will be available in .txt and .cha formats according to the norms of CHILDES (Child Language Data Exchange System) using the software CLAN (MacWhinney 2000). The texts in .cha format will include an orthographically standardized version of each text with syntactic annotation.